🚩MySQL

目录
索引
🌟 什么是聚簇索引?
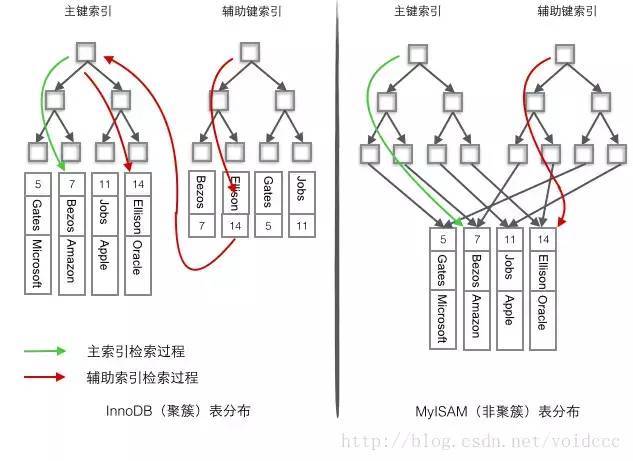
对于每张表,每个索引都对应一个独立的 B+ 树:
- 聚簇索引(一个):叶子节点保存了行数据,有且只有一个聚簇索引。
- 主键 pk > 唯一索引 unique > 自动生成 row_id
- 非聚簇索引(多个):叶子节点关联主键,指向了数据的对应行,若没有覆盖索引则需要回表走聚簇索引。
在可重复读(RR)隔离级别下:聚簇索引更新 = 替换,非聚簇索引更新 = 删除+新建
聚簇索引的优点:
- 在操作系统中,采用的是按页存储,聚簇索引的主键和行数据是一起被载入内存的。当访问叶子节点的时候,这一页就已经加载到了 Buffer 中,可以直接叶子节点中拿到行数据,减少访问磁盘的时间。
- 辅助索引使用主键作为"指针",而不是使用地址值作为指针的好处是,当出现页分裂的时候,不需要去维护地址值,相当于是一个空间换时间的思想。
- 适用于排序的场合、取出范围数据的场合。
- 在业务上,可以通过表主键id来聚合数据,通过聚簇索引可以减少磁盘I/O
索引分类
逻辑维度
- 唯一索引 unique:可以为空,但最多一个空
- 联合索引:最左匹配原则
- 全文索引 full text :支持文本模糊查询用于 char、varchar、text
- 前缀索引:可以选择在 varchar(128)的列上选择前 32 个字符作为索引
- 主键索引 primary key:不能为空
物理维度分为聚簇/非聚簇:叶子节点是否存储行数据
覆盖索引:索引包含某次查询的所有列
哈希索引:Innodb 和 MyISAM 都不适用,Memory 引擎支持。
选择索引列
- 数据量大、查询频繁的表,涉及 where、orderby、groupby 频繁的字段
- 区分度高的字段建立唯一索引或放在左边
- 字符串类型优先使用前缀索引,占用空间更小
not null约束
不选择索引情况
- 被频繁更新的字段
- 长期未使用的索引:sys 库的
schema_unused_indexes视图
🌟索引失效情况?
- 没有覆盖索引,如 select *
- 联合索引未遵循最左前缀原则
- Mysql 从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分
- 例如索引是 key index (a,b,c)。 可以支持 a 、a,b 、a,b,c 3 种组合进行查找,但不支持 b,c 进行查找。
- 范围查询右边的列会失效,范围过大也会导致全表扫描
- 在索引列上运算操作
- like ‘%abc’
- or 的前后条件中有一个列没有索引,涉及的索引也失效
- in()查询时,应该尽可能减少值列表的长度,避免查询转化成过长的 OR 子句,以及避免在查询中使用 NULL 值。
事务
事务执行过程

宕机情形:
- 在 redo log 刷新到磁盘(事务提交)之前,都是回滚 undo log。
- 如果在 redo log 已经刷新到磁盘,在 MySQL 重启之后就会回放这个 redo log,以纠正数据库里的数据。
隔离级别
- 脏读:读到其他事务未提交的数据
- 不可重复读:同一事务内,先后读取的数据不同,因为其他事务 update 或 delete 会影响结果集。
- 幻读:同一事务内,先后读取的 count 不同。例如,查询时没有某 id,插入时 id 已存在。
- 原因:加锁后,不锁定间隙,其他事务可以 INSERT,导致相同的查询在不同的时间得到不同的结果。
- 解决方案:使用临键锁,对于使用了唯一索引等唯一查询条件,InnoDB 只锁定索引记录,不锁定间隙;对于其他查询条件,InnoDB 会锁定扫描到的索引范围,通过临键锁来阻止其他会话在这个范围中插入新值。
- RU 读未提交:脏读、不可重复读、幻读都会出现
- RC 读已提交:解决脏读,每一次快照读时生成 ReadView 读取自己的新快照
- 多数数据库默认
- 仅支持基于行的 bin log
- 当一个事务启动时,数据库会为该事务创建一个版本链,该版本链包含了数据库中所有数据对象的所有版本。当事务读取数据时,数据库会根据事务的启动时间戳选择相应的版本,并且在版本链中添加一个新的版本,以保证该事务所读取的数据不会被其他事务修改。
- RR 可重复读:解决不可重复读,仅第一次生成 ReadView 的活跃事务 m_ids,后续复用(一致性快照)
- MVCC = multiple version concurrent control 多版本并发控制
- 目的:高并发场景下,锁的性能差,MVCC 可以避免读写阻塞
- DB_ROW_ID:隐藏列
- DB_ROLL_PIR:回滚指针,指向这条记录的上一版本
- 版本链存储在 undo log 中
- DB_TRX_ID:最近修改的事务 id
- 理论上 RR 存在幻读,但 MySQL 临键锁 next key lock 解决了幻读问题
- 问:如何保证 REPEATABLE READ 级别绝对不产⽣幻读?
- 答:在 SQL 中加⼊for update (排他锁) 或 lock in share mode (共享锁)语句实现。就是锁住了可能造成幻读的数据,阻⽌数据的写⼊操作。
- MVCC = multiple version concurrent control 多版本并发控制
- Serializable 串行化
- 加锁读:在每一行数据上都加锁,导致大量的超时和锁争用的问题,只有在非常需要确保数据一致性并且可以接受没有并发的情况下,才考虑采用该级别
事务特性 ACID
- Atomic 原子性
- 一个事务要么全部提交,要么全部回滚
- 通过 undo log 记录逻辑日志,回滚时通过逆操作来恢复
- 保存位置:system tablespace(mysql5.7) 或 undo tablespaces(mysql8.0)
- Consistent 一致性
- 事务总是由一种状态转换为另一种状态,而不会停留在执行中的某个状态
- A、I、D 同时作用,保证了 C(一致性)
- Isolate 隔离性
- 读写隔离:MVCC,undo log 版本链(从最新记录依次指向最旧记录的链表),ReadView 在 RC 和 RR 的不同
- 写写隔离:锁
- Ddurable 持久性
- 事务只要提交了,那么数据库中的数据也永久的发生了变化
- 通过 redo log 增量记录数据页的物理变化,服务宕机时用来同步数据,先写日志,再写磁盘
- 日志文件:【ib_logfile0】【ib_logfile1】
- 日志缓冲:innodb_logh_buffer_size
- 强刷:fsync()
优化
🌟SQL 优化经验?
- 只检索需要的列,避免 select *,主查询聚簇索引,子查询覆盖索引
- 将 HAVING 中部分条件提前到 WHERE 里
- 将 RR 降低为 RC,避免临键锁引发死锁,提高性能。
- 可以通过缓存第一次数据,来避免第二次查询,来保证几乎全部事务内部对某一数据都只读取一次
- 可以单独指定 Session 或者事务的隔离级别。
- 减小事务粒度,常 COMMIT,尽早释放锁
- **用 union all **代替 union(去重、排序消耗性能)
- where 语句中不使用表达式,防止索引失效
- 能用 inner join(优先以小表驱动大表) 就不用 left/right join。
- 用 EXPLAIN 返回的预估行数
| |
- 使用视图
- 用IN代替OR
如何使用慢 SQL 优化?
| |
找到慢 SQL 之后,用 EXPLAIN 命令分析:
- possible_key:可能用到的索引
- key:实际命中的索引
- key_len:索引占用的大小
- rows:扫描的行数
- filtered:所需数据占 rows 的比例
- extra:额外的优化建议
- Using where;Using Index 用到索引,不用回表
- Using index condition 用到索引,需要回表
- type:性能从好到差
- system:mysql 自带的表
- const:根据主键查询
- eq_ref:主键索引/唯一索引
- ref:索引查询
- range:范围查询
- index:索引树扫描
- all:全盘扫描
应用
连接池对比
- HikariCP: SpringBoot 框架的默认连接池,性能好
- Druid:Alibaba 开源的连接池,能防 SQL 注入,带有监控功能
分库分表 - sharding-sphere 中间件
原因:数据库遇到了性能瓶颈。
- 水平分库:应对大数据,对性能要求不同的数据进行分库
sync_binlog = 0/1 - 垂直分库:根据业务进行拆分微服务
- 垂直分表:冷热数据分离(零零播项目中的 user、streamer、owner)
读写分离:主库写,从库读。会涉及一致性问题,解决方案:主从自动切换(keepAlived、云服务提供)
数据迁移
| |
- 加快导入速度
- 关闭唯一性检查
- 开启 extended-insert 将多行合并为一个 INSERT 语句
- 关闭 binlog,迁移后再开启
- 调整 redolog 时机
- 数据校验
- 先读 binlog,不一致再读源表,以源表为准。
- 先读从库,不一致再读主库,以主库为准。
- 增量同步数据
- 时间戳
- binlog
基础概念

结构化查询语言的 6 个部分
DDL:Data Define Language,数据定义语言
- CREATE、ALTER、DROP
DML:Data Manipulation Language,数据操作语言
- INSERT、UPDATE、DELETE
DQL:Data Query Language,数据查询语言
- SELECT、WHERE、ORDER BY、GROUP BY、HAVING
TCL:Transactional Control Language,事务控制语言,确保 DML 影响的所有行及时得以更新
- COMMIT、SAVEPOINT、ROLLBACK
DCL:Data Control Language,数据控制语言,实现权限控制
- GRANT、REVOKE
CCL:Cursor Control Language,指针控制语言
- DECLARE CURSOR、FETCH INTO、UPDATE WHERE CURRENT
MySQL 中的锁
InnoDB 引擎加锁的本质是锁住索引记录(可以理解为 B+树的叶子节点)。在可重复读 RR 的隔离级别下,
- 一般都加临键锁,左开右闭 (防止幻读)
- 上界无穷间隙锁
- 唯一索引等值查询记录锁
区别
binlog 、redolog 和 undolog 的区别?
binlog 是二进制日志,redolog 和 undolog 是事务日志。
- binlog: 所有引擎增量记录逻辑日志(二进制)
- 数据库还原
- 🌟主从同步(Canal 类中间件本质是把自己伪装成从节点):
- 主库提交,将 DDL 与 DML 数据写入 binlog;
- 从库上启动复制
- 创建IO线程连接主库
- 主库创建 binlog dump 线程读取数据库事件并发送给 IO线程
- 从库的IO线程获取到事件数据后,更新从库的中继日志 relay log
- 从库上的SQL线程读取中继日志 relay log中更新的数据库事件,并应用
sync_binlog = 0:写入 page cache 就算成功(默认)sync_binlog = N:每提交 N 次就刷新到磁盘,N 越小性能越差。默认是 1,可以调大,改善性能,但需要承受数据丢失的风险。
- redolog:InnoDB 循环记录物理日志(某个页的修改),大小固定,写到结尾时(
write pos追上check point),会回到开头循环写日志,提供了崩溃恢复能力,保证了持久性。- 先更新 buffer pool,再写 redo log,等事务结束后刷盘到磁盘
- 顺序写,性能优于随机写
innodb_flush_log_at_trx_commit= 1 默认,表示事务提交后刷盘,最安全,其次 2,0,但性能会更好。
- undolog: 记录逻辑相反操作逻辑日志,用于回滚
- delete:记录主键逻辑删除
- insert:记录主键
- update
- 没有更新主键:主键+原值
- 更新主键:delete+insert
Innodb 和 MyISAM 的区别?
- innodb 支持事务和外键
- innodb 默认表锁,使用索引检索条件时是行锁,而 myisam 是表锁(每次更新增加删除都会锁住表)
- innodb 和 myisam 的索引都是基于 b+树,但 innodb 的 b+树的叶子节点是存放数据的,myisam 的 b+树的叶子节点是存放指针的
- innodb 是聚簇索引,必须要有主键,一定会基于主键查询,但是辅助索引就会查询两次,myisam 是非聚簇索引,索引和数据是分离的,索引里保存的是数据地址的指针,主键索引和辅助索引是分开的。
- innodb 不存储表的行数,所以 select count( _ )的时候会全表查询,而 myisam 会存放表的行数,select count(_)的时候会查的很快。
- MyISAM 存储限制 256TB,更适合低并发、弱一致性场景;Innodb 存储限制 64TB,更适合高并发、更新频繁的场景。
B+树与 B 树的区别?
- B 树中每个节点都存储数据,B+树只有叶子节点存储数据 =》 IO 次数少
- 聚簇索引:行数据
- 辅助索引:行的主键
- 非聚簇索引:行所在的地址
- B+树的键可能会在非叶子节点重复出现
- B+树的叶子节点之间通过双向链表连接 =》 适合范围查询
delete/truncate/drop 的区别?
- DELETE 删除表中的行,不删除表本身
- 项目中一般使用逻辑删除,增加 deleted 字段
- TRUNCATE 删除表,再创建一个空表
- 初始化数据
- DROP 删除表