警告
本文最后更新于 2021-11-08,文中内容可能已过时。
一、基础知识
1. 函数式编程
- 函数式编程中的函数的主要意思是“把函数作为一等值”,不过它也常常隐含着第二层意思,即“执行时在元素之间无互动”。
- 引用透明性——“没有可感知的副作用”
- 不改变对调用者可见的变量。返回的结果基于参数却没有修改任何一个传入的参数
- 不进行I/O
- 不抛出异常
- 选择使用引用透明的函数
- 也允许函数内部执行一些非函数式的操作,只要这些操作的结果不会暴露给系统中的其他部分。作为函数式的程序,你的函数或方法调用的库函数如果有副作用,你必须设法隐藏它们的非函数式行为,否则就不能调用这些方法。
- 被称为“函数式”的函数或方法都只能修改本地变量。除此之外,它引用的对象都应该是不可修改的对象。
- 要被称为函数式,函数或者方法不应该抛出任何异常。旦抛出异常,就意味着结果被终止了;不再像我们之前讨论的黑盒模式那样,由return返回一个恰当的结果值。 —— 请使用Optional类型
- Optional类:它是一个容器对象,可以包含,也可以不包含一个值。Optional中有方法来明确处理值不存在的情况,这样就可以避免NullPointer异常了。
★2. lambda表达式:行为参数化(灵活、简洁)
- 函数式接口(用@FunctionalInterface标记)与匿名内部类:

函数式接口(加前缀:Int、Double、Long)
- Predicate: T -> boolean (谓词)
- Consumer: T -> void
- Function: T,R -> R
- Supplier:() -> R
范型T只能绑定到引用类型
闭包:闭包就是一个函数的实例,且它可以无限制地访问那个函数的非本地变量。现在,Java 8的Lambda和匿名类可以做类似于闭包的事情:它们可以作为参数传递给方法,并且可以访问其作用域之外的变量。但有一个限制:它们不能修改定义Lambda的方法的局部变量的内容。这些变量必须是隐式最终的。可以认为Lambda是对值封闭,而不是对变量封闭。
方法引用:根据已有的方法实现来创建Lambda表达式
- 指向静态方法

- 指向任意类型实例方法

- 指向现有对象的实例方法

构造函数引用:ClassName :: new
比较器链:

二、函数式数据处理
★1. 流

- 中间操作:返回stream类型
- filter:排除元素,Predicate,T -> boolean
- map:提取信息,Function<T,R>, T -> R
- limit:截断流(有状态-有界)
- skip:与limit互补(有状态-有界)
- sorted:排序,Comparator, (T,T) -> int(有状态-无界)
- distinct:去重(有状态-无界)
- flatMap:让你把一个流中的每个值都换成另一个流,然后把所有的流连接起来成为一个流
- 终端操作:返回非stream类型
- collect:转换成其他格式(返回集合)
- count:计数(返回long)
- forEach:遍历(返回void)
- (以下都是短路求值)
- anyMatch:至少匹配一个(返回boolean)
- allMatch:都匹配(返回boolean)
- noneMatch:都不匹配(返回boolean)
- findAny:找到任意(返回Optional类)
- findFirst:找到第一个,在并行上限制更多,如果不关心返回的元素是哪个,请使用findAny。(返回Optional类)
- reduce: BinaryOperator ,(T, T) -> T (返回Optional类)(有状态-有界)

- 流只能消费一次。
1-1. 原始类型流特化
Java 8引入了三个原始类型特化流接口来解决这个问题:IntStream、DoubleStream和LongStream,分别将流中的元素特化为int、long和double,从而避免了暗含的装箱成本。要记住的是,这些特化的原因并不在于流的复杂性,而是装箱造成的复杂性——即类似int和Integer之间的效率差异。
1-2. 映射到数据流

1
2
3
4
| //将Stream转换为数值流
IntStream intStream = menu.stream().mapToInt(Dish::getCalories);
//将数值流转换为Stream
Stream<Integer> stream = intStream.boxed();
|
range是不包含结束值的,而rangeClosed则包含结束值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| Stream<int[]> pythagoreanTriples =
IntStream.rangeClosed(1, 100).boxed()
.flatMap(a ->
IntStream.rangeClosed(a, 100)
.filter(b -> Math.sqrt(a*a + b*b) % 1 == 0)
.mapToObj(b ->
new int[]{a, b, (int)Math.sqrt(a * a + b * b)})
);
Stream<double[]> pythagoreanTriples2 =
IntStream.rangeClosed(1, 100).boxed()
.flatMap(a ->
IntStream.rangeClosed(a, 100)
.mapToObj(
b -> new double[]{a, b, Math.sqrt(a*a + b*b)})
.filter(t -> t[2] % 1 == 0));
|
1-3. 无限流(斐波那契数列)
- iterate:使用iterate的方法则是纯粹不变的:它没有修改现有状态,但在每次迭代时会创建新的元组
1
2
3
4
5
6
| Stream.iterate(new int[]{0, 1},
t -> new int[]{t[1],t[0] + t[1]})
.limit(10)
.map(t -> t[0])
.forEach(System.out::println);
//这段代码将生成斐波纳契数列:0, 1, 1, 2, 3, 5, 8, 13, 21, 34…
|
- generate:getAsInt()在调用时会改变对象的状态,由此在每次调用时产生新的值
1
2
3
4
5
6
7
8
9
10
11
12
| IntSupplier fib = new IntSupplier(){
private int previous = 0;
private int current = 1;
public int getAsInt(){
int oldPrevious = this.previous;
int nextValue = this.previous + this.current;
this.previous = this.current;
this.current = nextValue;
return oldPrevious;
}
};
IntStream.generate(fib).limit(10).forEach(System.out::println);
|
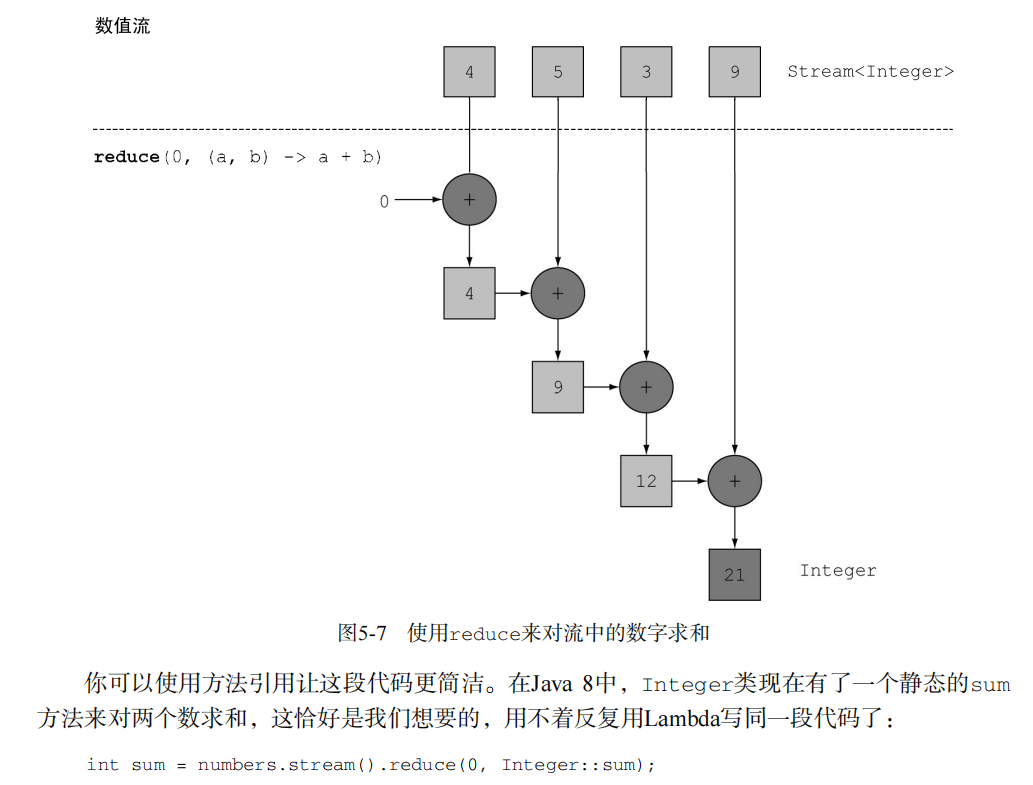
1-4. reduce

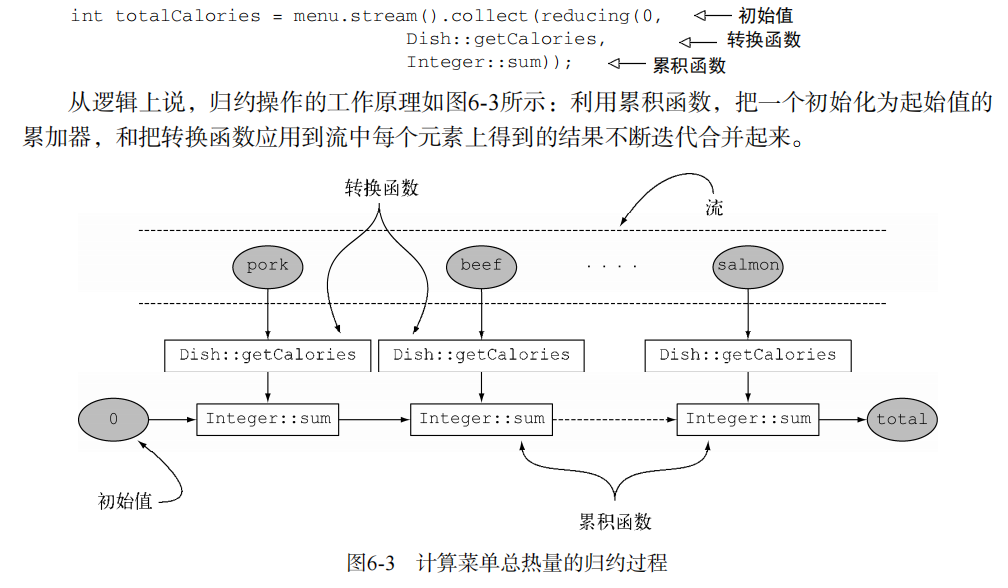
1-5. 收集器

Collector接口
1
2
3
4
5
6
7
8
9
10
| //T是流中要收集的项目的泛型。
//A是累加器的类型,累加器是在收集过程中用于累积部分结果的对象。
//R是收集操作得到的对象(通常但并不一定是集合)的类型。
public interface Collector<T, A, R> {
Supplier<A> supplier();
BiConsumer<A, T> accumulator();
Function<A, R> finisher();
BinaryOperator<A> combiner();
Set<Characteristics> characteristics();
}
|
自己实现收集器

List<Dish> dishes = menuStream.collect(new ToListCollector<Dish>());
★2. 用 Optional 取代 null
null的检查只会掩盖问题,并未真正地修复问题
1
2
3
4
5
6
7
8
| //1. 声明一个空的Optional
Optional<Car> optCar = Optional.empty();
//2. 依据一个非空值创建Optional
//如果car是一个null,这段代码会立即抛出一个NullPointerException
Optional<Car> optCar = Optional.of(car);
//3. 可接受null的Optional
//如果car是null,那么得到的Optional对象就是个空对象
Optional<Car> optCar = Optional.ofNullable(car);
|


1
2
3
4
5
6
| public String getCarInsuranceName(Optional<Person> person) {
return person.flatMap(Person::getCar)
.flatMap(Car::getInsurance)
.map(Insurance::getName)
.orElse("Unknown"); //如果Optional的结果值为空,设置默认值
}
|
Optional 通过类型系统让你的域模型中隐藏的知识显式地体现在你的代码中,换句话说,你永远都不应该忘记语言的首要功能就是沟通,即使对程序设计语言而言也没有什么不同。声明方法接受一个Optional参数,或者将结果作为Optional类型返回,让你的同事或者未来你方法的使用者,很清楚地知道它可以接受空值,或者它可能返回一个空值。

2-1. Optional 的方法
- get():如果变量存在,它直接返回封装的变量值,否则就抛出一个NoSuchElementException异常
- orElse(T other):允许你在Optional对象不包含值时提供一个默认值
- orElseGet(Supplier<? extends T> other):是orElse方法的延迟调用版,Supplier 方法只有在Optional对象不含值时才执行调用。如果创建默认值是件耗时费力的工作,你应该考虑采用这种方式(借此提升程序的性能),或者你需要非常确定某个方法仅在Optional为空时才进行调用,也可以考虑该方式(这种情况有严格的限制条件)。
- orElseThrow(Supplier<? extends X> exceptionSupplier):自定义抛出异常
- ifPresent(Consumer<? super T>):能在变量值存在时执行一个作为参数传入的方法,否则就不进行任何操作。
不推荐使用基础类型的Optional,因为基础类型的Optional不支持map、flatMap以及filter方法,而这些却是Optional类最有用的方法。
2-2. 实战案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| // 使用 Optional 前
public int readDuration(Properties props, String name) {
String value = props.getProperty(name);
if (value != null) {
try {
int i = Integer.parseInt(value);
if (i > 0) {
return i;
}
} catch (NumberFormatException nfe) { }
}
return 0;
}
// 使用 Optional 后
public int readDuration(Properties props, String name) {
return Optional.ofNullable(props.getProperty(name))
.flatMap(OptionalUtility::stringToInt)
.filter(i -> i > 0)
.orElse(0);
}
|
3. 内部迭代
三、高效 Java 8 编程
1. 各版本变化
- Java 5:引入 for-each 循环,替代迭代器
- Java 7:引入菱形操作符<>,使用范型
- Java 8:lambda表达式,函数式编程,让设计模式更灵活
🌟2. 设计模式
2-1. 策略模式
场景:根据不同条件进行筛选。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| // 1. 不使用 Lambda 表达式
public interface ValidationStrategy {
boolean execute(String s);
}
public class IsAllLowerCase implements ValidationStrategy {
public boolean execute(String s){
return s.matches("[a-z]+");
}
}
public class IsNumeric implements ValidationStrategy {
public boolean execute(String s){
return s.matches("\\d+");
}
}
public class Validator{
private final ValidationStrategy strategy;
public Validator(ValidationStrategy v){
this.strategy = v;
}
public boolean validate(String s){
return strategy.execute(s);
}
}
Validator numericValidator = new Validator(new IsNumeric());
boolean b1 = numericValidator.validate("aaaa"); //FALSE
Validator lowerCaseValidator = new Validator(new IsAllLowerCase ());
boolean b2 = lowerCaseValidator.validate("bbbb"); //TRUE
// 2. 使用 Lambda 表达式
Validator numericValidator =
new Validator((String s) -> s.matches("[a-z]+"));
boolean b1 = numericValidator.validate("aaaa");
Validator lowerCaseValidator =
new Validator((String s) -> s.matches("\\d+"));
boolean b2 = lowerCaseValidator.validate("bbbb");
|
2-2. 模板方法
场景:需要采用某个算法的框架,同时又希望有一定的灵活度,能对它的某些部分进行改进。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| // 1. 不使用 Lambda 表达式
abstract class OnlineBanking {
public void processCustomer(int id){
Customer c = Database.getCustomerWithId(id);
makeCustomerHappy(c);
}
abstract void makeCustomerHappy(Customer c);
}
public void processCustomer(int id, Consumer<Customer> makeCustomerHappy){
Customer c = Database.getCustomerWithId(id);
makeCustomerHappy.accept(c);
}
// 2. 使用 Lambda 表达式
public void processCustomer(int id, Consumer<Customer> makeCustomerHappy){
Customer c = Database.getCustomerWithId(id);
makeCustomerHappy.accept(c);
}
new OnlineBankingLambda().processCustomer(1337, (Customer c) ->
System.out.println("Hello " + c.getName());
|
2-3. 观察者模式
场景:某些事件发生时(比如状态转变),subject需要自动地通知其他observer。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| // 1. 不使用 Lambda 表达式
interface Observer {
void notify(String tweet);
}
class NYTimes implements Observer{
public void notify(String tweet) {
if(tweet != null && tweet.contains("money")){
System.out.println("Breaking news in NY! " + tweet);
}
}
}
class Guardian implements Observer{
public void notify(String tweet) {
if(tweet != null && tweet.contains("queen")){
System.out.println("Yet another news in London... " + tweet);
}
}
}
interface Subject{
void registerObserver(Observer o);
void notifyObservers(String tweet);
}
class Feed implements Subject{
private final List<Observer> observers = new ArrayList<>();
public void registerObserver(Observer o) {
this.observers.add(o);
}
public void notifyObservers(String tweet) {
observers.forEach(o -> o.notify(tweet));
}
}
Feed f = new Feed();
f.registerObserver(new NYTimes());
f.registerObserver(new Guardian()); //observe ↓↓↓
f.notifyObservers("The queen said her favourite book is Java 8 in Action!");
//输出:
//Yet another news in London...
//The queen said her favourite book is Java 8 in Action!
// 2. 使用 Lambda 表达式
// 简化了观察者的代码
interface Subject{
void registerObserver(Observer o);
void notifyObservers(String tweet);
}
class Feed implements Subject{
private final List<Observer> observers = new ArrayList<>();
public void registerObserver(Observer o) {
this.observers.add(o);
}
public void notifyObservers(String tweet) {
observers.forEach(o -> o.notify(tweet));
}
}
Feed f = new Feed();
f.registerObserver((String tweet) -> {
if(tweet != null && tweet.contains("money")){
System.out.println("Breaking news in NY! " + tweet);
}
});
f.registerObserver((String tweet) -> {
if(tweet != null && tweet.contains("queen")){
System.out.println("Yet another news in London... " + tweet);
}
});
f.notifyObservers("The queen said her favourite book is Java 8 in Action!");
//输出:
//Yet another news in London...
//The queen said her favourite book is Java 8 in Action!
|
2-4. 责任链模式
场景:创建处理对象序列(比如操作序列)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| // 1. 不使用 Lambda 表达式
public abstract class ProcessingObject<T> {
protected ProcessingObject<T> successor;
public void setSuccessor(ProcessingObject<T> successor){
this.successor = successor;
}
public T handle(T input){
T r = handleWork(input);
if(successor != null){
return successor.handle(r);
}
return r;
}
abstract protected T handleWork(T input);
}
public class HeaderTextProcessing extends ProcessingObject<String> {
public String handleWork(String text){
return "From Raoul, Mario and Alan: " + text;
}
}
public class SpellCheckerProcessing extends ProcessingObject<String> {
public String handleWork(String text){
return text.replaceAll("labda", "lambda");
}
}
ProcessingObject<String> p1 = new HeaderTextProcessing();
ProcessingObject<String> p2 = new SpellCheckerProcessing();
p1.setSuccessor(p2);
String result = p1.handle("Aren't labdas really sexy?!!");
System.out.println(result);
// 2. 使用 Lambda 表达式
UnaryOperator<String> headerProcessing =
(String text) -> "From Raoul, Mario and Alan: " + text;
UnaryOperator<String> spellCheckerProcessing =
(String text) -> text.replaceAll("labda", "lambda");
Function<String, String> pipeline =
headerProcessing.andThen(spellCheckerProcessing);
String result = pipeline.apply("Aren't labdas really sexy?!!");
|
2-5. 工厂模式
场景:无需向客户暴露实例化的逻辑就能完成对象的创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| // 1. 不使用 Lambda 表达式
public class ProductFactory {
public static Product createProduct(String name){
switch(name){
case "loan": return new Loan();
case "stock": return new Stock();
case "bond": return new Bond();
default: throw new RuntimeException("No such product " + name);
}
}
}
Product p = ProductFactory.createProduct("loan");
// 2. 使用 Lambda 表达式
Supplier<Product> loanSupplier = Loan::new;
Loan loan = loanSupplier.get();
final static Map<String, Supplier<Product>> map = new HashMap<>();
static {
map.put("loan", Loan::new);
map.put("stock", Stock::new);
map.put("bond", Bond::new);
}
public static Product createProduct(String name){
Supplier<Product> p = map.get(name);
if(p != null) return p.get();
throw new IllegalArgumentException("No such product " + name);
}
|
3. peek查看中间值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| List<Integer> numbers = Arrays.asList(2, 3, 4, 5);
List<Integer> result =
numbers.stream()
.peek(x -> System.out.println("from stream: " + x))
.map(x -> x + 17)
.peek(x -> System.out.println("after map: " + x))
.filter(x -> x % 2 == 0)
.peek(x -> System.out.println("after filter: " + x))
.limit(3)
.peek(x -> System.out.println("after limit: " + x))
.collect(toList());
/*
输出:
from stream: 2
after map: 19
from stream: 3
after map: 20
after filter: 20
after limit: 20
from stream: 4
after map: 21
from stream: 5
after map: 22
after filter: 22
after limit: 22
*/
|
★4. 接口的默认方法
1
2
3
4
5
6
| public interface Sized {
int size();
default boolean isEmpty() {
return size() == 0;
}
}
|
4-1. 继承和实现冲突的问题

4-2. 三条规则
- 首先,类或父类中显式声明的方法,其优先级高于所有的默认方法。
- 如果用第一条无法判断,方法签名又没有区别,那么选择提供最具体实现的默认方法的接口。函数签名相同时,优先选择拥有最具体实现的默认方法的接口,即如果B继承了A,那么B就比A更加具体。
- 最后,如果冲突依旧无法解决,继承了多个接口的类必须通过显式覆盖和调用期望的方法,显式地选择使用哪一个默认方法的实现。

5. 组合式异步编程
5-1. 并发与并行

★5-2. Future -> CompletableFuture
Stream和CompletableFuture的设计都遵循了类似的模式:它们都使用了Lambda表达式以及流水线的思想。从这个角度,你可以说 CompletableFuture和Future的关系就跟Stream和Collection的关系一样。
- Collection主要是为了存储和访问数据,而Stream则主要用于描述对数据的计算
- 通过Stream你可以对一系列的操作进行流水线,通过map、filter或者其他类似的方法提供行为参数化,它可有效避免使用迭代器时总是出现模板代码。
- 类似地,CompletableFuture提供了像thenCompose、thenCombine、allOf这样的操作,对Future涉及的通用设计模式提供了函数式编程的细粒度控制,有助于避免使用命令式编程的模板代码。

实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| List<Shop> shops = Arrays.asList(new Shop("BestPrice"),
new Shop("LetsSaveBig"),
new Shop("MyFavoriteShop"),
new Shop("BuyItAll"));
// 1. 顺序查询 耗时 4032ms
public List<String> findPrices(String product) {
return shops.stream()
.map(shop -> String.format("%s price is %.2f",
shop.getName(), shop.getPrice(product)))
.collect(toList());
}
// 2. 并行流 耗时 1180ms
public List<String> findPrices(String product) {
return shops.parallelStream()
.map(shop -> String.format("%s price is %.2f",
shop.getName(), shop.getPrice(product)))
.collect(toList());
}
// 3. 使用工厂方法supplyAsync创建CompletableFuture对象 耗时 2005ms
List<CompletableFuture<String>> priceFutures =
shops.stream()
.map(shop -> CompletableFuture.supplyAsync(
() -> String.format("%s price is %.2f",
shop.getName(), shop.getPrice(product))))
.collect(toList());
return priceFutures.stream()
.map(CompletableFuture::join)
.collect(toList());
//处理5个商店,顺序执行版本耗时5025ms,并行流版本耗时2177ms,而CompletableFuture版本耗时2006ms
//处理9个商店,并行流版本耗时3143ms,而CompletableFuture版本耗时3009ms
|
这里使用了两个不同的Stream流水线,而不是在同一个处理流的流水线上一个接一个地放置两个map操作——这其实是有缘由的。考虑流操作之间的延迟特性,如果你在单一流水线中处理流,发向不同商家的请求只能以同步、顺序执行的方式才会成功。因此,每个创建CompletableFuture对象只能在前一个操作结束之后执行查询指定商家的动作、通知join方法返回计算结果。

5-3. 使用定制的执行器

1
2
3
4
5
6
7
8
9
10
11
12
13
| private final Executor executor =
Executors.newFixedThreadPool(Math.min(shops.size(), 100),
new ThreadFactory() {
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
//使用守护线程——这种方式不会阻止程序的关停
t.setDaemon(true);
return t;
}
});
//改进之后,使用CompletableFuture方案的程序处理5个商店仅耗时1021ms,处理9个商店时耗时1022ms。
CompletableFuture.supplyAsync(() -> shop.getName() + " price is " +
shop.getPrice(product), executor);
|
守护进程
Java程序无法终止或者退出一个正在运行中的线程,所以最后剩下的那个线程会由于一直等待无法发生的事件而引发问题。与此相反,如果将线程标记为守护进程,意味着程序退出时它也会被回收
5-4. CompletableFuture 与 parallelStream 的选择
- 如果你进行的是计算密集型的操作,并且没有I/O,那么推荐使用Stream接口,因为实现简单,同时效率也可能是最高的(如果所有的线程都是计算密集型的,那就没有必要创建比处理器核数更多的线程)。
- 反之,如果你并行的工作单元还涉及等待I/O的操作(包括网络连接等待),那么使用CompletableFuture灵活性更好,你可以像前文讨论的那样,依据等待/计算,或者W/C的比率设定需要使用的线程数。这种情况不使用并行流的另一个原因是,处理流的流水线中如果发生I/O等待,流的延迟特性会让我们很难判断到底什么时候触发了等待。
5-5. join 与 get 方法,构造同步和异步操作
CompletableFuture类中的join方法和Future接口中的get有相同的含义,并且也声明在Future接口中,它们唯一的不同是join不会抛出任何检测到的异常。
future.thenCompose
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public List<String> findPrices(String product) {
List<CompletableFuture<String>> priceFutures =
shops.stream()
//1. 获取价格
.map(shop -> CompletableFuture.supplyAsync(
() -> shop.getPrice(product), executor))
//2. 解析报价
.map(future -> future.thenApply(Quote::parse))
//3. 为计算折扣价格构造Future
//如果不希望等到第一个任务完全结束才开始第二项任务,使用thenCombine方法
.map(future -> future.thenCompose(quote ->
CompletableFuture.supplyAsync(
() -> Discount.applyDiscount(quote), executor)))
.collect(toList());
return priceFutures.stream()
.map(CompletableFuture::join)
.collect(toList());
}
//thenCompose方法像CompletableFuture类中的其他方法一样,也提供了一个以Async后缀结尾的版本thenComposeAsync。
//通常而言,名称中不带Async的方法和它的前一个任务一样,在同一个线程中运行;而名称以Async结尾的方法会将后续的任务提交到一个线程池,所以每个任务是由不同的线程处理的。
//就这个例子而言,第二个CompletableFuture对象的结果取决于第一个CompletableFuture,所以无论你使用哪个版本的方法来处理CompletableFuture对象,对于最终的结果,或者大致的时间而言都没有多少差别。
//我们选择thenCompose方法的原因是因为它更高效一些,因为少了很多线程切换的开销。
|

future.thenCombine
1
2
3
4
5
6
7
| Future<Double> futurePriceInUSD =
CompletableFuture.supplyAsync(() -> shop.getPrice(product))
.thenCombine(
CompletableFuture.supplyAsync(
() -> exchangeService.getRate(Money.EUR, Money.USD)),
(price, rate) -> price * rate
);
|
6. 新的日期和时间API
6-1. LocalDate 、 LocalTime 和 LocalDateTime
1
2
3
4
5
6
| LocalDate date = LocalDate.of(2014, 3, 18);
LocalDate date1 = LocalDate.parse("2014-03-18");
LocalTime time1 = LocalTime.parse("13:45:20");
LocalDateTime dt = LocalDateTime.of(2014, Month.MARCH, 18, 13, 45, 20);
LocalDate date2 = dt.toLocalDate();
LocalTime time2 = dt.toLocalTime();
|
Temporal接口定义了如何读取和操纵为时间建模的对象的值。
6-2. 定义 Duration 或 Period
很自然地你会想到,我们需要创建两个Temporal对象之间的duration。Duration类的静态工厂方法between就是为这个目的而设计的。
1
2
3
4
5
6
7
| // Duration 对应 time
Duration d1 = Duration.between(time1, time2);
Duration d2 = Duration.between(dateTime1, dateTime2);
// Period 对应 date
Period tenDays = Period.ofDays(10);
Period threeWeeks = Period.ofWeeks(3);
Period twoYearsSixMonthsOneDay = Period.of(2, 6, 1);
|
截至目前,我们介绍的这些日期时间对象都是不可修改的,这是为了更好地支持函数式编程,确保线程安全,保持领域模式一致性而做出的重大设计决定。
6-3. 操纵日期
1
2
3
4
5
6
7
8
9
10
11
12
| // 1. 绝对修改
LocalDate date1 = LocalDate.of(2014, 3, 18);
LocalDate date2 = date1.withYear(2011); //2011-03-18
LocalDate date3 = date2.withDayOfMonth(25); //2011-03-25
LocalDate date4 = date3.with(ChronoField.MONTH_OF_YEAR, 9);//2011-09-25
// 2. 相对修改
LocalDate date1 = LocalDate.of(2014, 3, 18);
LocalDate date2 = date1.plusWeeks(1); //2014-03-25
LocalDate date3 = date2.minusYears(3); //2011-03-25
LocalDate date4 = date3.plus(6, ChronoUnit.MONTHS); //2011-09-25
//上面的plus方法也是通用方法,它和minus方法都声明于Temporal接口中
|
6-4. 设计一个NextWorkingDay类
1
2
3
4
5
6
7
8
9
10
| TemporalAdjuster nextWorkingDay = TemporalAdjusters.ofDateAdjuster(
temporal -> {
DayOfWeek dow =
DayOfWeek.of(temporal.get(ChronoField.DAY_OF_WEEK));
int dayToAdd = 1;
if (dow == DayOfWeek.FRIDAY) dayToAdd = 3;
if (dow == DayOfWeek.SATURDAY) dayToAdd = 2;
return temporal.plus(dayToAdd, ChronoUnit.DAYS);
});
date = date.with(nextWorkingDay);
|
6-5. 日期和 String 转换
1
2
3
4
5
6
7
8
9
10
11
12
| // 使用 LocalDate 的 format 和 parse 方法
LocalDate date = LocalDate.of(2014, 3, 18);
String s1 = date.format(DateTimeFormatter.BASIC_ISO_DATE); //20140318
String s2 = date.format(DateTimeFormatter.ISO_LOCAL_DATE); //2014-03-18
LocalDate date1 = LocalDate.parse("20140318", DateTimeFormatter.BASIC_ISO_DATE);
LocalDate date2 = LocalDate.parse("2014-03-18", DateTimeFormatter.ISO_LOCAL_DATE);
// 自定义模式
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("dd/MM/yyyy");
LocalDate date1 = LocalDate.of(2014, 3, 18);
String formattedDate = date1.format(formatter);
LocalDate date2 = LocalDate.parse(formattedDate, formatter);
|
四、超越 Java 8
1. 基于“尾-递”的阶乘
1
2
3
4
5
6
| static long factorialTailRecursive(long n) {
return factorialHelper(1, n);
}
static long factorialHelper(long acc, long n) {
return n == 1 ? acc : factorialHelper(acc * n, n-1);
}
|
这种形式的递归是非常有意义的,现在我们不需要在不同的栈帧上保存每次递归计算的中间值,编译器能够自行决定复用某个栈帧进行计算。实际上,在factorialHelper的定义中,立即数(阶乘计算的中间结果)直接作为参数传递给了该方法。再也不用为每个递归调用分配单独的栈帧用于跟踪每次递归调用的中间值——通过方法的参数能够直接访问这些值。

2. 科里化(curry)
1
2
3
4
5
6
7
| static DoubleUnaryOperator curriedConverter(double f, double b){
return (double x) -> x * f + b;
}
DoubleUnaryOperator convertCtoF = curriedConverter(9.0/5, 32);
DoubleUnaryOperator convertUSDtoGBP = curriedConverter(0.6, 0);
DoubleUnaryOperator convertKmtoMi = curriedConverter(0.6214, 0);
|
3. Scala
- 声明变量
s : String - 创建集合
val authorsToAge = Map("Raoul" -> 23, "Mario" -> 40, "Alan" -> 53) - val 表示不可变,var表示可变
- 支持任意大小的元组
1
2
3
4
5
| val book = (2014, "Java 8 in Action", "Manning") //元组类型为(Int, String, String)
val numbers = (42, 1337, 0, 3, 14)
println(book._1) //2014
println(numbers._4) //3
|
- Scala中的Stream可以记录它曾经计算出的值,所以之前的元素可以随时进行访问。除此之外,Stream还进行了索引,所以Stream中的元素可以像List那样通过索引访问。注意,这种抉择也附带着开销,由于需要存储这些额外的属性,和Java 8中的Stream比起来,Scala版本的Stream内存的使用效率变低了,因为Scala中的Stream需要能够回溯之前的元素,这意味着之前访问过的元素都需要在内存“记录下来”(即进行缓存)。
- Option:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| //Java
public String getCarInsuranceName(Optional<Person> person, int minAge) {
return person.filter(p -> p.getAge() >= minAge)
.flatMap(Person::getCar)
.flatMap(Car::getInsurance)
.map(Insurance::getName)
.orElse("Unknown");
}
//Scala
def getCarInsuranceName(person: Option[Person], minAge: Int) =
person.filter(_.getAge() >= minAge)
.flatMap(_.getCar)
.flatMap(_.getInsurance)
.map(_.getName).getOrElse("Unknown")
//在前面的代码中,你使用的是_.getCar(并未使用圆括号),而不是_.getCar() (带圆括号)。Scala语言中,执行方法调用时,如果不需要传递参数,那么函数的圆括号是可以省略的。
|
4. 闭包
闭包是一个函数实例,它可以不受限制地访问该函数的非本地变量。
不过Java 8中的Lambda表达式自身带有一定的限制:它们不能修改定义Lambda表达式的函数中的本地变量值。这些变量必须隐式地声明为final。
这些背景知识有助于我们理解“Lambda避免了对变量值的修改,而不是对变量的访问”。
5. trait
Scala还提供了另一个非常有助于抽象对象的特性,名称叫trait。它是Scala为实现Java中的接口而设计的替代品。trait中既可以定义抽象方法,也可以定义带有默认实现的方法。trait同时还支持Java中接口那样的多继承,所以你可以将它们看成与Java 8中接口类似的特性,它们都支持默认方法。trait中还可以包含像抽象类这样的字段,而Java 8的接口不支持这样的特性。那么,trait就类似于抽象类吗?显然不是,因为trait支持多继承,而抽象类不支持多继承。Java支持类型的多继承,因为一个类可以实现多个接口。现在,Java 8通过默认方法又引入了对行为的多继承,不过它依旧不支持对状态的多继承,而这恰恰是trait支持的。
1
2
3
4
5
6
7
8
9
10
11
12
13
| trait Sized{
var size : Int = 0
def isEmpty() = size == 0 //带默认实现的isEmpty方法
}
class Empty extends Sized
println(new Empty().isEmpty())
class Box
val b1 = new Box() with Sized //在对象实例化时构建trait
println(b1.isEmpty())
val b2 = new Box()
b2.isEmpty() //编译错误:因为Box类的声明并未继承Sized
|

